This chapter describes the run-time system that was developed to allow loadable schedulers to control CPU allocation in a general-purpose operating system. The most important aspect of this description is the programming model made available to loadable schedulers, which includes: when and why different notifications are delivered to schedulers, what actions schedulers can take when responding to notifications, concurrency control in the scheduler infrastructure, and the trust model for loadable schedulers.
The hierarchical scheduler infrastructure (HSI) is a code library that resides in the kernel of a general-purpose operating system. The goals of the HSI are (1) to allow hierarchical schedulers to efficiently allocate CPU time in such a way that the CPU requirements of soft real-time applications are met and (2) to reduce the cost of developing CPU schedulers as much as possible without violating the first goal. To meet the second goal, the HSI provides a well-defined programming interface for schedulers, insulating developers from the details of a particular OS such as the kernel concurrency model, complex thread state transitions, and the multiprocessor programming model. The following criteria ensure that the goals are met:
An additional requirement, that each scheduler must be allocated a distribution of CPU time conforming to the guarantee that it was promised, is not addressed by the HSI, which is merely a mechanism for allowing schedulers to be loaded into the OS kernel. Guarantees and scheduler composition are described in Chapters 5 and 6. A prototype implementation of the HSI in Windows 2000 is described in Chapter 9.
Schedulers are passive code libraries that may either be built into the kernel or loaded into the kernel at run time. At least one scheduler must be built into the HSI in order to boot the OS: thread scheduling is required early in the boot process, at a time when it would be difficult to get access to the filesystem where loadable schedulers are stored. The HSI keeps a list of all schedulers (both loaded and built in), indexed by scheduler name. Scheduler implementations must not contain any static data--all scheduler state must be referenced through a scheduler instance pointer.
Scheduler instances are active entities in the scheduling hierarchy. They may be identified either by name or by a scheduler instance pointer, which points to a block of per-instance data that is allocated when the instance is created.
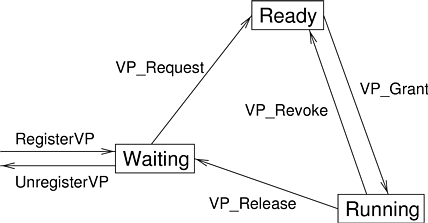
Virtual processors (VPs) are the principal mechanism that schedulers use to communicate with each other. Each virtual processor is shared between exactly two schedulers, and represents the potential for the parent scheduler to provide a physical CPU to the child scheduler. The separation of the scheduler instance and virtual processor abstractions is an important element of multiprocessor support in HLS. Virtual processors have a state--at any time they are either running, ready, or waiting. A virtual processor is mapped to a physical CPU only when it is running.
The CPU schedulers in general-purpose and real-time operating systems are usually state machines with some auxiliary local data. Control passes to the scheduler after some event of interest happens, at which point the scheduler updates its local data, possibly makes a scheduling decision, and then relinquishes control of the CPU in order to let a thread run. The hierarchical scheduling infrastructure was designed to efficiently support this kind of scheduler. Because function calls are a cheap, structured mechanism for control transfer, loadable schedulers use them to communicate with each other and with the OS. The function calls used to implement these notifications, as well as notifications that the HSI gives to schedulers, are listed in Table 4.1.
|
Each scheduler is related to one or more other schedulers in the hierarchy through shared virtual processors. In any given relationship, a scheduler is either a parent or a child, depending on whether it is above or below the other scheduler in the scheduling hierarchy. Related schedulers notify each other of changes in the states of virtual processors they share.
Two schedulers become related when the (potential) child registers a virtual processor with the parent. To do this the child calls the parent’s RegisterVP function. Similarly, when a child wishes to break a relationship with a parent, it calls the parent’s UnregisterVP function.
A newly registered VP is in the waiting state. In order to get control of a physical processor, a scheduler must call its parent’s VP_Request function, which puts the VP into the ready state pending the fulfillment of the request. At some point (possibly immediately) the parent calls the child’s VP_Grant function indicating that the request has been granted. Before granting the request the parent sets the state of the VP to running and sets its Proc field to the number of one of the system’s physical processors; processors in an n CPU machine are numbered 0..n - 1. When a scheduler gains control over a physical processor, it may then grant one of its own pending requests. A physical processor that was granted to one of a scheduler’s VPs may be revoked by the parent scheduler at any time. When a VP is in a state other than running, its Proc field must be set to the special value NO_PROC.
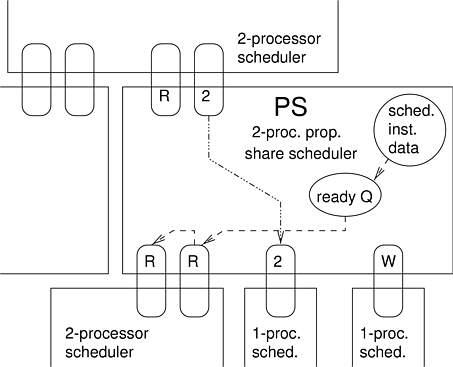
A conceptual view of this relationship from the point of view of a proportional share (PS) scheduler is shown in Figure 4.1. Rounded boxes represent virtual processors. Since the PS scheduler shares two virtual processors with its parent scheduler, it is able to control the allocation of at most two physical processors. Since it shares four virtual processors with its children, it is multiplexing at most two physical processors among at most four virtual processors. From left to right, the VPs that PS shares with its parent are ready and running on processor 2. From left to right, the VPs that PS shares with its children are ready, ready, running on processor 2, and waiting.
In addition to sending and receiving notifications about virtual processor state changes, a scheduler may send a message to its parent. Messages have no intrinsic meaning--the schedulers must agree on how to interpret them. In practice, messages are most often used to set the scheduling parameters of a VP. In the case that a scheduler is not able to send the type of message that it needs to request a particular kind of scheduling behavior, the scheduler infrastructure may send messages on its behalf in response to requests made from user-level using the HLSCtl interface. For example, if a time-sharing scheduler were to be assigned a CPU reservation in order to ensure fast response time and reasonable throughput for the interactive applications that it schedules, the infrastructure would send the message to the reservation scheduler requesting that it provide a CPU reservation to the time-sharing scheduler.
The scheduler infrastructure also sends other kinds of notifications to schedulers. The Init function is used to set up a new instance of a scheduler, and Deinit is used to shut down an instance, in a manner analogous to constructors and destructors in an object-oriented system. Init is guaranteed to be the first notification a scheduler receives and Deinit the last. A scheduler will never receive the Deinit call while it has any children. Schedulers can set timers; when a timer expires the HSI uses the TimerCallback function to notify it. When debugging is enabled, the scheduler infrastructure invokes each scheduler CheckInvar function from time to time: this tells schedulers to run internal consistency checks in order to catch bad scheduler states as early as possible, facilitating debugging.
The virtual processor interface is similar to, and was inspired by, the work on scheduler activations by Anderson et al. [3]. Scheduler activations are a mechanism for giving user-level thread schedulers running on multiprocessor machines enough information to allow them to make informed scheduling decisions. This is accomplished by notifying the user-level scheduler each time a physical processor is added to or revoked from the pool of processors available to an address space. The invariant is maintained that each user-level scheduler always knows the number of physical processors that are allocated to it, except when the final processor is revoked from it--then it learns of the revocation when a processor is next allocated to it. The applicability of scheduler activations to hierarchical scheduling is no accident: the in-kernel and user-level thread schedulers that Anderson et al. were addressing form a two-level scheduling hierarchy.
Besides generalizing the two-level hierarchy to
any number of levels, the most important differences between HLS
virtual processors and scheduler activations are that (1) HLS
allows the root scheduler to be chosen arbitrarily and (2) all HLS
schedulers reside in the kernel. Making the root scheduler
replaceable is necessary to make real-time guarantees to non-root
schedulers and to applications. Putting all schedulers in the
kernel allows the HSI to maintain a slightly stronger invariant
than scheduler activations: each scheduler immediately learns when
a processor is revoked from it, even the last one; this simplifies
accurate accounting of CPU time. Also, a potential inefficiency of
scheduler activations is avoided: scheduler activations increase
the number of thread preemptions in the case that a processor is
revoked from an address space, since a second preemption is
required to tell the thread scheduler about the first one. The
notification mechanism used by the HSI is virtual function call. On
a 500 MHz PC running Windows 2000 a virtual function call takes
about 20 ns and preempting a thread takes about 7 ![]() s.
s.
The HSI makes several functions available to loadable schedulers. They are:
Thread states in a general-purpose operating system may be more complicated than simply being ready, waiting, or running. For example, Windows 2000 has seven thread states: initialized, ready, waiting, transition, standby, running, and terminated. To meet the goal of simplifying the programming model for scheduler developers, HLS has only three virtual processor states, as shown in Figure 4.2.This design decision is motivated by the fact the additional states are not relevant to thread schedulers, and consequently schedulers should not be aware of them. The states of VPs that are not registered with a scheduler are undefined and are not relevant.
All loadable schedulers are required to correctly implement the HLS protocol. Protocol violations are likely to result in unpredictable behavior and may crash the OS. The HLS protocol is derived from the requirement that, no matter what the scheduling hierarchy does internally, the end result of each notification sent to the scheduling hierarchy must be that each physical processor is running exactly one thread. This ignores transient processor activities such as switching contexts, handling interrupts, etc.--these do not concern loadable schedulers. The protocol is as follows:
The HLS protocol describes how hierarchical schedulers interact with each other, but not how the collection of hierarchical schedulers as a whole interacts with the rest of the operating system.
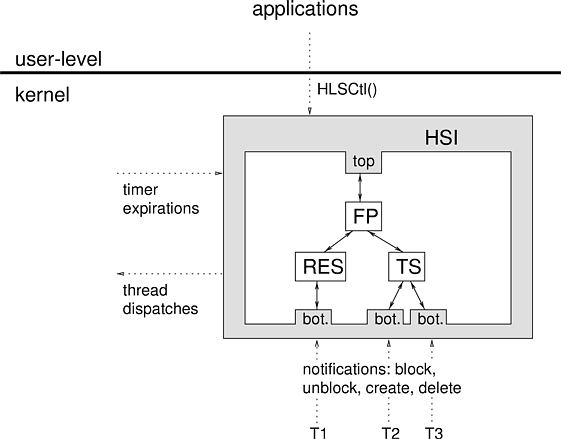
Normal hierarchical schedulers are stackable in the sense that they import and export the same interface. There are two special HLS schedulers that are not stackable: the top scheduler and bottom scheduler. They are not stackable since they are simply glue code for interfacing loadable schedulers with the rest of the operating system--they make no interesting scheduling decisions. The relationships between loadable schedulers and top and bottom schedulers are shown in Figure 4.3.
|
An instance of the bottom scheduler is automatically created for each thread in the system. Its lifetime is the same as the lifetime of the thread with which it is associated. The purpose of the bottom scheduler is to convert thread actions such as creation, blocking, unblocking, and exiting into HLS notifications. Each bottom scheduler instance creates a single VP, which it registers with a default scheduler when the thread is created. If the thread was created in a ready state, the bottom scheduler automatically requests scheduling for its VP. When the request is granted, it dispatches the thread. When the thread blocks it implicitly releases the processor, and when the thread exits it implicitly unregisters the VP and then destroys the VP and the bottom scheduler instance. Table 4.2.
|
The scheduling hierarchy is designed to execute in a serialized environment. In effect, it must be protected by a lock, meaning that even on a multiprocessor only one CPU may be executing scheduling code at a time. This design decision was made for three reasons. First, the scheduler programming model would have become considerably more difficult if scheduler authors had to worry not only about protecting shared data, but also about potential deadlocks that could occur if the hierarchy were concurrently processing several notifications. Second, since scheduler operations tend to be fast, the relative overhead of fine-grained locking inside the hierarchy would have been high. Third, all scheduling activity is serialized in Windows 2000, the operating system in which the HSI has been prototyped. Serializing the scheduling hierarchy makes it difficult to scale to large multiprocessors--this is a limitation of the current HSI design.
Hierarchical schedulers can almost always preempt user threads,1 but schedulers themselves are not preemptible except by interrupt handlers. It is important to recognize the distinction between preemptible threads and preemptible schedulers. Schedulers execute quickly, typically taking tens of microseconds or less to make a scheduling decision, and may not be preempted by any event except a hardware interrupt. The decisions made by schedulers (for example, to run thread 17 on processor 0) are relatively long-lived, typically lasting for milliseconds or tens of milliseconds. Any scheduling decision made by a hierarchical scheduler may be overridden by a scheduler between it and the root of the scheduling hierarchy.
If more than one notification is raised while the scheduling hierarchy is processing a different notification, the order in which the new notifications are processed is undefined. For example, assume that one processor on a 4-way machine is being used by an EDF scheduler to calculate the earliest deadline of a task. While it is performing this calculation, threads on two other processors block, sending notifications to the HSI. The order in which these release notifications are sent to schedulers in the hierarchy cannot be assumed to be either (1) the first notification raised is delivered first, or (2) the notification coming from the highest-priority thread is delivered first. The order is undefined because access to the scheduling hierarchy is handled by low-level system primitives such as spinlocks and interprocessor interrupts that do not implement queuing or otherwise make ordering guarantees. Rather, the scheduling hierarchy relies on the fact that scheduler operations, spinlock acquires and releases, and interprocessor interrupts are very fast (typically taking a small number of microseconds) relative to application deadlines (typically 10 ms or more), and therefore they are unlikely to cause application deadlines to be missed. In other words, a basic simplifying assumption made by HLS is that scheduling decisions are fast compared to application deadlines.
One of the goals of HLS is to make it easier to develop new schedulers. Unfortunately, the low-level programming model exported by symmetric multiprocessor (SMP) machines is difficult because it is impossible for one processor to atomically induce a context switch on another processor. Rather, scheduler code running on one CPU must send an interprocessor interrupt (IPI) to the other processor, which, at some point in the future, causes scheduling code on the other processor to be called. In between the sending and receiving of the interprocessor interrupt, an arbitrary number of events can happen (threads blocking, unblocking, etc.), resulting in an arbitrary number of calls into the scheduler infrastructure. This implies that on a multiprocessor, a scheduler’s view of which threads are running on which processors can become out of date.
To protect loadable schedulers from having to have two representations of the set of threads being scheduled (the desired and actual set of scheduled threads), the scheduler infrastructure hides from loadable schedulers the details of which thread is actually running on each processor. It presents a uniform, atomic view of the set of processors to the scheduling hierarchy, and works in the background to make the actual set of scheduled threads converge to the desired set of threads as quickly as possible.
For example, assume that a loadable scheduler running on processor 0 attempts to cause a thread running on processor 1 to be moved to processor 2. This results in two interprocessor interrupts: the first one sent to processor 1 and the second to processor 2. Before or in between the delivery of the IPIs, any number of scheduling notifications can be sent to the scheduling hierarchy, causing the loadable schedulers’ view of the hierarchy to become inconsistent with the actual mapping of threads to processors. These issues are discussed in more detail in Section 9.2.3.
Schedulers that implement processor affinity attempt to avoid moving threads between CPUs on a multiprocessor machine because moving threads’ working sets between the caches on different processors is expensive. Torrellas et al. [89] show that cache affinity can reduce overall execution time of numeric workloads by up to 10%. The HSI indirectly supports processor affinity because the top scheduler always grants the same physical processor to a given VP, allowing processor affinity to be propagated to schedulers lower in the hierarchy. As Ford and Susarla [24] observe, processor affinity will only work reliably in a scheduling hierarchy if all schedulers between a given scheduler and the root support processor affinity.
The HSI supports both space sharing and time sharing of multiprocessor machines. In this section, unlike the rest of the dissertation, “time sharing” refers to a way of using a machine, rather than a kind of scheduler. Space sharing means dedicating different processors (or groups of processors) on a multiprocessor to different applications. By running a different root scheduler on each processor, completely different scheduling behaviors could be given to different applications or groups of applications. Time sharing involves treating a multiprocessor as a pool of processors to be shared between applications.
Space sharing and time sharing behaviors can be mixed. For example, real-time applications can be pinned to particular processors (space sharing) while allowing interactive and batch applications to freely migrate between processors to balance load (time sharing). In general, interactive and batch applications place unpredictable demands on the system and benefit from the flexibility of time sharing behavior, while real-time tasks with predictable execution times can be space-shared effectively.
Priority inversion can prevent multimedia applications from meeting their deadlines. While it would be useful to implement a mechanism for avoiding priority inversions, HLS currently assumes that priority inversions are avoided manually. This can be accomplished by having high- and low-priority threads avoid sharing synchronization primitives, by manually raising the priority of threads before entering critical sections (that is, by manually implementing the priority ceiling protocol), or by ensuring that threads that share synchronization primitives are scheduled periodically, bounding the duration of any priority inversions.
Some priority inversions in HLS could be prevented by having a blocking thread pass its scheduling parameters to the thread that it blocks on. This is the approach taken by migrating threads [23] and CPU inheritance scheduling [24]. However, applications may block on resources such that no thread can be identified to pass scheduling parameters to. For example, a thread may block on a network device or a disk driver. Also, synchronization primitives may be used in idiomatic ways (for example, using a semaphore as a condition variable instead of a mutex) making it difficult or impossible to identify which thread will eventually wake a blocking thread. Sommer [78] presents a good survey of the issues involved in removing priority inversion in Windows NT.
The HLSCtl() system call was added to Windows 2000 to allow user-level applications to interact with the HSI. If an implementation of the resource manager existed, it would be the only process allowed to make this call. In the current prototype implementation, any thread may do so. When the HLSCtl command is called, the HSI parses the arguments passed to the command and then runs the appropriate function to service the command. The operations that can be performed through HLSCtl are:
This has proven to be a useful set of primitives for the set of loadable schedulers that has been implemented for the prototype version of HLS.
Loadable schedulers are trusted. Like other loadable kernel modules, they have access to the entire kernel address space, giving them the ability to crash the OS, read and write privileged information, control any hardware device attached to the computer, or even to completely take over the operating system.
This does not imply that untrusted users cannot load new schedulers into the kernel; rather, it means that the set of schedulers that are candidates for being loaded into the kernel must have been approved by the administrator of a particular system. Approved schedulers could be stored in a secure location or, equivalently, the HSI could store cryptographic checksums of approved schedulers in order to ensure that no non-approved scheduler is loaded into the kernel.
A loadable scheduler must correctly provide any guarantees about the allocation of CPU time that it made and also correctly implement the hierarchical scheduling protocol. A partial list of actions that a hierarchical scheduler must not take is the following:
The motivation for trusting loadable schedulers is twofold. First, trusting loadable device drivers has proven to be workable in all major general-purpose operating systems. Second, creating a language or operating system environment for implementing schedulers that meets the simultaneous goals of high performance, type safety, constrained resource usage, and guaranteed termination would have been a research project in itself.
Since a multiprocessor hierarchical scheduler may require considerable development and testing effort, it may be desirable to implement simplified schedulers in order to test new scheduling algorithms with minimal implementation effort. Section 9.4.3 presents some anecdotal evidence about the amount of time taken to develop various schedulers.
A scheduler that registers only one VP with its parent is a uniprocessor scheduler. These schedulers can run on multiprocessor machines, but each instance can only control the allocation of a single CPU.
A root-only scheduler is written under the assumption that each of its virtual processors will have exclusive access to a physical processor. Therefore, the VP_Revoke callback will never be called and does not need to be implemented.
Anecdotal evidence suggests that a uniprocessor, root-only proportional share scheduler can be implemented in well under a day. A few more hours of effort were required to remove the root-only assumption.
HLS provides fully generic scheduler support in the sense that it gives schedulers all of the information about events occurring in the operating system that they need in order to make scheduling decisions. Functions are also provided for sending domain-specific information from applications to schedulers and between schedulers. Still, there are some restrictions on what schedulers can and cannot do, that may make it difficult to implement some kinds of schedulers.
Since schedulers run in a serialized environment at a higher priority than any thread, it is essential that all scheduler operations (including schedulability analysis) be completed very quickly--in tens of microseconds, preferably. Some kinds of schedulers that include complicated searches or planning-based approaches will be difficult to implement in this environment. For example, each time a new CPU reservation is requested, Rialto/NT [37] must potentially perform a complex computation to generate a new scheduling plan. When there are more than 60 existing CPU reservations, adding a new reservation may take up to about 5 ms. Since it is unacceptable to suspend all scheduling operations for 5 ms, the HLS concurrency model would have to be adjusted to support a scheduler like Rialto/NT. The most straightforward solution would be to use optimistic concurrency control to build a scheduling plan without the protection of the scheduler lock. In fact, this was the approach taken by Rialto/NT.
To use optimistic concurrency control Rialto/NT atomically (while holding the scheduler lock) copies all information that it needs to build a new scheduling plan into a temporary location and then releases the lock to allow the system to operate normally during the plan computation. Once the scheduling plan has been built, Rialto/NT reacquires the scheduler lock. The new plan must be thrown away if any event has happened during its construction that invalidates it. The difficulty of supporting compute-intensive schedulers, rather than being a property of the HLS concurrency model, is an inherent problem caused by the fact that a slow scheduler must either halt all thread operations while it runs, guaranteeing that a valid schedule will be constructed, or construct the plan concurrently with normal thread operation, which risks building an invalid plan.
Some scheduling algorithms require the ability to send asynchronous notifications to user-level applications. For example, SMART [67] supports the time constraint abstraction that allows an application to request a certain amount of CPU time before a deadline. If SMART informs an application that a time constraint is feasible, but the constraint later becomes infeasible (for example, due to the awakening of a higher-priority task), SMART may notify the application of the infeasible constraint, potentially allowing the application to avoid performing a useless computation. Although the HSI does not currently support sending asynchronous notification to applications, this facility could be added using abstractions commonly found in general-purpose operating systems (e.g. signals in Unix-like operating systems and APCs in Windows NT/2000).
Finally, the HSI provides no facility for network communications, which would be required to support gang scheduling, cluster co-scheduling, and other coordinated scheduling services. These classes of schedulers could be implemented by adding communication facilities to HLS or by implementing schedulers that cooperate with a user-level task that shares synchronization information with other machines and passes the resulting information to the scheduler.
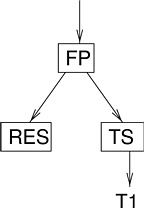
This section illustrates the operation of the hierarchical scheduling infrastructure using an example. Assume a uniprocessor PC that is running the scheduling hierarchy shown in Figure 4.4 .Initially there are three scheduler instances excluding top and bottom schedulers, which are not shown in this figure. A command shell thread is blocked while waiting for user input. Since no VP has requested service, the top scheduler is running the idle thread.
|
Each time the user presses a key, the keyboard device driver wakes up T1, the command shell thread. T1’s bottom scheduler translates the awakening into a VP_Request notification that it sends to its VP, which has been registered with the time-sharing scheduler (TS). The time-sharing scheduler, upon receiving this notification, must similarly request the CPU using its VP, and the fixed-priority scheduler (FP) does the same thing. When the top scheduler receives a request, it immediately grants it; FP passes the grant through to TS and then to T1’s bottom scheduler, which dispatches the thread. After processing the keystroke, T1 releases the processor and the VP_Release notification propagates up the hierarchy until it reaches the top scheduler, which then dispatches the idle thread.
Assume that the user’s keystrokes eventually form a command that launches a real-time application. A new thread T2 is created, also belonging to the default scheduler TS. When this thread’s bottom scheduler requests scheduling, TS must decide which of the two threads to run; if it is the new thread, TS will revoke the processor that it had previously granted to T1 and grant it to T2.
Assume that T2 requests real-time scheduling. T2 executes the HLSCtl system call, which causes the scheduler infrastructure to unregister its VP from TS and to register it with the reservation scheduler (RES). The HSI also sends a message to RES requesting a CPU reservation with parameters that were passed to the kernel as part of the system call T2 made. If the reservation request is rejected, the HSI moves T2 back to TS; otherwise, T2 now has a CPU reservation.
The reservation scheduler uses a timer to receive a callback each time T2’s budget needs to be replenished. At that point, if T2 is ready to run, it requests scheduling from FP. FP, by design, will always revoke the CPU from TS in response to a request from RES. TS must pass the revocation along to T1, and then FP can grant the CPU to RES, which schedules T2. To preempt T2 when its budget expires, RES arranges to wake up using a timer, revokes the CPU from T2, and then releases its VP, allowing FP to schedule TS again.
This simple example is merely intended to illustrate the interaction of schedulers, the HSI, and the operating system. More complicated motivating examples will appear in upcoming chapters. In each figure that depicts a scheduling hierarchy, schedulers will be shown in rectangular boxes and parent/child relationships (virtual processors) will be indicated by arrows.
This chapter has described the design of the hierarchical scheduler infrastructure and the execution environment that it provides for loadable schedulers; the programming interface for schedulers is described in more detail in Appendix B. In terms of the low-level operations described in this chapter, schedulers are simply event-driven state machines that sometimes get to control the allocation of one or more physical CPUs. However, a higher-level aspect of schedulers’ behavior is critically important in a real-time system: this is the pattern of CPU time that a scheduler provides to entities that it schedules, which must conform to the guarantee that the scheduler made. Guarantees are the subject of the next two chapters.