|
The previous chapter described the guarantee mechanism for composing schedulers. This chapter presents several applications of scheduler composition. The first section describes how to compute the parameters for a CPU reservation that, when given to a rate monotonic scheduler, allows that scheduler to schedule all periodic threads in a multi-threaded real-time application. The second part of this chapter shows that complex idiomatic scheduling behavior can be composed using simple schedulers as components. The final section describes some additional guarantee issues, such as how multiprocessors are supported and limitations of the guarantee system.
Many multimedia applications are structured as groups of cooperating threads. For example, as Jones and Regehr [39] describe, when the Windows Media Player (the streaming audio and video application that ships with Windows systems) is used to play an audio file, it creates five threads with periods ranging from 45 ms to 1000 ms. One way to apply real-time scheduling techniques to such an application would be to assign a CPU reservation with appropriate period and amount to each thread in the application. Another way would be to assign a single CPU reservation to the entire application, and then use a rate monotonic scheduler to schedule the individual application threads. The resulting scheduling abstraction is similar to the multi-thread activity provided by Rialto [40], except that threads within a Rialto activity are scheduled earliest deadline first when they hold a time constraint, and round-robin otherwise. Also, no method was presented for calculating the amount of period of the CPU reservation that each Rialto activity should request. This section presents such a method.
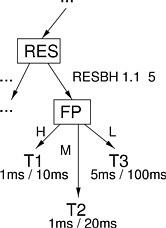
Figure 6.1 shows a portion of a scheduling hierarchy that includes a per-application reservation. Threads T1, T2, and T3 all belong to the same application, and respectively require 1 ms of CPU time every 10 ms, 1 ms every 20 ms, and 5 ms every 100 ms. The fixed-priority scheduler FP schedules the threads rate monotonically by assigning priorities to the threads in order of increasing period: T1 gets the highest priority, T2 gets the middle priority, and T3 gets the lowest priority. Then, the rate monotonic scheduler is given a basic CPU reservation of 1.1 ms / 5 ms. The method that will be presented in Section 6.1.2 can be used to show that this reservation is sufficient to allow all three threads to meet their deadlines.
|
Reasons that a per-application reservation might be preferable to per-thread reservations include the following:
There are also several reasons why a per-application reservation might not be a good idea:
A thorough investigation of the tradeoffs between per-thread and per-application reservations is beyond the scope of this work.
This section presents a method for calculating the parameters of a CPU reservation that, when provided to a rate monotonic scheduler, allows that scheduler to meet the CPU requirements of an application comprised of multiple periodic threads. The approach is to use static-priority analysis to test the schedulability of the group of threads comprising the application plus a ghost thread that represents the time not available to the application because the reservation scheduler is scheduling a different application. Since the ghost thread cannot be “preempted” by the application, it must have the highest priority in the analysis.
The following lemma establishes the equivalence between a continuous, non-preemptive CPU reservation and static priority scheduling including a ghost task. This equivalence is important because it will allow us to expand the domain of applicability of static priority analysis to hierarchical task sets.
Lemma 6.1. Assume a thread T1 is scheduled at low priority by a fixed priority scheduler that (1) is given the guarantee ALL, and (2) schedules at high priority a thread T2 that has period y and amount (y - x), and has no release jitter. Then, the scheduling behavior received by T1 is the same as it would receive if it were given the guarantee RESNH x y.
Theorem 6.1. If a static priority scheduler that is given the guarantee ALL can schedule the task set containing the threads of a multi-threaded application plus a “ghost” task with period y and amount (y - x) that runs at the highest priority, then the application can also be scheduled using a rate monotonic scheduler that is given a continuous, non-preemptible CPU reservation with amount x and period y.
The usefulness of Theorem 6.1 is limited by the fact that real schedulers cannot easily provide continuous, non-preemptible CPU reservations--the schedulability analysis for task sets containing non-preemptive tasks that require significant amounts of CPU time is very pessimistic. The following lemma will be used to support a theorem that relaxes the assumption of non-preemptive reservations.
Lemma 6.2. Assume a thread T1 is scheduled at low priority by a fixed priority scheduler that (1) is given the guarantee ALL, and (2) schedules at high priority a thread T2 that has period y and amount (y - x), and has release jitter of up to x time units. Then, the scheduling behavior received by T1 is the same as it would receive if it were given the guarantee RESBH x y.
Theorem 6.2. If a static priority scheduler that is given the full CPU bandwidth can schedule the task set containing the threads of a multi-threaded application plus a “ghost” task with period y and amount (y - x) that runs at the highest priority and that also has release jitter allowing it to run at any offset within its period, then the application threads can also be scheduled using a rate monotonic scheduler that is given a basic CPU reservation with amount x and period y time units.
To apply Theorem 6.2 in practice, we use a version of static priority analysis that takes release jitter into account [87]. Release jitter gives a task the freedom to be released, or to become ready to run, at times other than the beginning of its period. For example, a task with release jitter could wait until the end of one period to run and then run at the beginning of the next period--the possibility of “back-to-back” task occurrences of course has a negative influence on the schedulability of any lower-priority tasks. The analogous situation for a thread scheduled by a basic reservation scheduler happens when it is scheduled at the beginning of one period and the end of the next.
Static priority analysis is a generalization of rate monotonic analysis that does not require thread periods and priorities to be coupled. The freedom that a basic reservation scheduler has to decide when, within a task’s period, to allocate CPU time to a task is modeled in the fixed priority analysis by giving the ghost task the freedom to be released at any time during its period. To decide whether an application task set in combination with a ghost task is schedulable, the worst-case response time of each task must be calculated. Since we assume that task deadlines are equal to task periods, the task set as a whole is schedulable if and only if the worst-case response time of each task is less than or equal to its period.
The following formulas and notation are from Tindell et al. [87]. For task i, let ri be the worst-case response time, Ci be the worst-case execution time, Ti be period, and Ji be the release jitter. Also, let hp(i) be the set of tasks with higher priority than i. Tasks are numbered from 1..n in decreasing order of priority. Task 1 is the ghost task, and its release jitter is Tj - Cj, the worst possible jitter that will still allow the ghost task to meet its deadline. Application threads 1..n are mapped to static-priority tasks 2..n + 1, and all application threads have zero release jitter. Then, the following formula
|
|
(6.1) |
|
|
(6.2) |
All parameters except for C1 and T1, the amount and period of the ghost task, are known. The problem is to find the largest possible amount and period for the ghost task that allows the combined task set to be schedulable. The period of the per-application reservation will then be T1 and the amount will be the time not used by the ghost reservation: T1 - C1.
Lacking a closed-form solution to this problem,
we solve it iteratively. Unfortunately, the solution is not well
defined since there are two unknowns. One way to constrain the
solution space would be to find the ghost reservation with the
largest utilization (i.e., that maximizes ![]() )
that still allows the resulting task set to be schedulable, and
then to search for the reservation having that utilization that has
the largest period (larger periods are desirable since they reduce
the expected number of unnecessary context switches). However,
better heuristics may be possible: to reduce unnecessary context
switches it may be acceptable to choose a ghost reservation with a
slightly smaller utilization than the largest possible utilization
if the period of the ghost reservation is significantly longer.
)
that still allows the resulting task set to be schedulable, and
then to search for the reservation having that utilization that has
the largest period (larger periods are desirable since they reduce
the expected number of unnecessary context switches). However,
better heuristics may be possible: to reduce unnecessary context
switches it may be acceptable to choose a ghost reservation with a
slightly smaller utilization than the largest possible utilization
if the period of the ghost reservation is significantly longer.
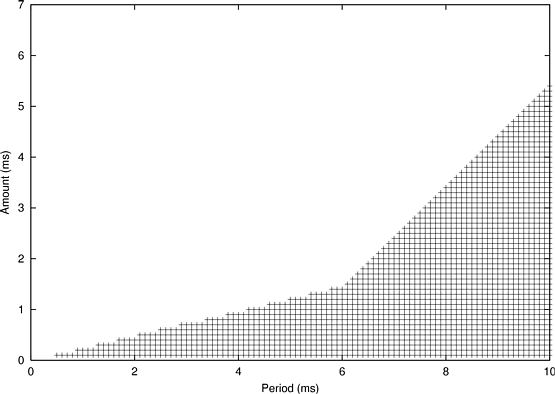
This section presents a concrete example of the calculation described in the previous section. The task set for the example was generated using the periods of the tasks in Windows Media Player [39]; the amount of CPU time required by each thread was fabricated. A task representing the Windows kernel mixer, a middleware thread that must also receive real-time scheduling for the Media Player to operate correctly, was added to the task set. All periods and amounts are listed in Table 6.1 ;their total utilization is 24.1% of the CPU.
|
The borders between the schedulable and unschedulable regions are roughly defined by the line between reservations with utilizations greater than and less than 24.1% (the line with a shallow slope), and the line between reservations with gaps longer and shorter than 9 ms (the line with steeper slope). Clearly, no reservation with utilization less than the utilization of the task set can guarantee its schedulability. The cause of the second line is less obvious--the “gap” in a reservation is the longest time interval that may not give any CPU time to the application being scheduled. To see why a basic CPU reservation of 1.5 ms / 6 ms has a maximum gap of 9 ms, observe that the reservation scheduler could schedule the application at the beginning of one period (leaving a 4.5 ms gap until the end of the period) and the end of the next period (leaving a second 4.5 ms gap). The total gap is then 9 ms long, which barely allows the Media Player thread with amount 1 and period 10 to meet its deadline (by being scheduled on either side of the gap). A heuristic search through the two-variable parameter space can be used to find a reservation assignment that is optimal in the sense that reserving either more time or at a shorter period would not allow that application to meet all deadlines.
Schedulers presented in the literature often provide scheduling behavior that is more complex than simple CPU reservations or proportional share scheduling, based on the hypothesis that certain complex scheduling behaviors are a good match for the kinds of overall scheduling behavior that real-world users and applications require.
This section demonstrates that a variety of complex schedulers can be synthesized from simple components, with the guarantee system helping to ensure correct composition. The fundamental insight is that scheduling policies can be implemented as much by the shape of the scheduling hierarchy as they are by schedulers themselves.
There are several reasons to build a complex scheduler on the fly from hierarchical components rather than implementing it as a fixed part of an operating system. First, modular schedulers can be more easily extended, restricted, and modified than monolithic schedulers. Second, the overhead associated with complex scheduling behaviors need only be incurred when complex behavior is required--complex arrangements of schedulers can be dismantled as soon as they are not needed. Finally, different complex scheduling behaviors can be combined in the same system. For example, the open system architecture defined by Deng et al. [18] provides support for multi-threaded real-time applications. However, the open system performs schedulability analysis based on worst-case execution times, making it difficult to schedule applications such as MPEG decoders whose worst-case CPU requirements are much larger than their average-case requirements. Probabilistic CPU reservations [16] were designed to solve exactly this problem. However, implementing them in the open system architecture (or vice versa) would be a difficult, time-consuming task. Using HLS, the two behaviors could be easily combined.
The implementors of schedulers providing CPU reservations have found it useful to characterize reservations as soft, guaranteeing that an application will receive a minimum amount of CPU time, or hard, guaranteeing a maximum as well as a minimum. Some multimedia applications limit their own CPU usage--at the beginning of each period they perform work and then block until the start of the next period. For these applications, it is irrelevant whether the guarantee they receive is hard or soft. For other applications, a soft CPU reservation may be useful if they can provide added value given extra CPU time. Hard reservations can be used to limit the processor usage of threads that may overrun, or that are CPU-bound.
Rialto [40], Rialto/NT [37], and the total bandwidth server [79] provide soft CPU reservations. The Rez scheduler presented in Section 9.3.2 provides hard CPU reservations, as does the constant bandwidth server [2]. The portable resource kernel for Linux [68] provides hard and soft CPU reservations, in addition to “firm” reservations, a special case of soft reservations that only receive extra CPU time when no other entity in the system requests it.
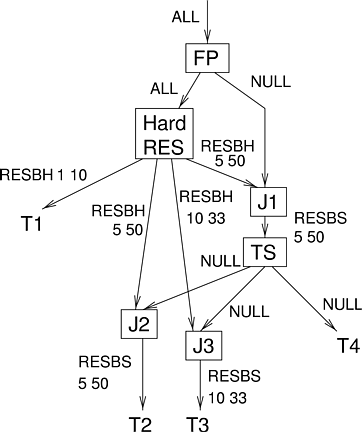
Figure 6.3 shows a scheduling hierarchy that can provide hard, firm, and soft CPU reservations. Each arc on the graph is labeled with the guarantee that is being provided. A fixed-priority (FP) scheduler at the root of the hierarchy allows a scheduler that provides hard CPU reservations to run whenever it has something to schedule. The join scheduler J1 combines a hard CPU reservation for the time-sharing scheduler (to ensure fast response time for interactive tasks) with any CPU time not used by the reservation scheduler. Threads 2 and 3 have soft CPU reservations provided by adding time-sharing scheduling behavior to their respective join schedulers. If J2 were scheduled by the time-sharing scheduler at a very low priority, than it could be said to have a firm CPU reservation--it would not get extra CPU time unless no other time sharing thread were runnable. Finally, Thread 4 is a normal time-sharing thread.
|
In a system containing a resource manager, probabilistic CPU reservations would be granted using a custom rule that performs the following actions: first, it creates a join scheduler and arranges for it to receive time-sharing scheduling; second, it moves the requesting thread to the join scheduler and finally, it requests a CPU reservation for the join scheduler. If all of these steps are successful, a soft CPU reservation has been successfully granted. In a system lacking a resource manager, a library routine or script would be used to provide a probabilistic CPU reservations by performing the same set of actions using the HLSCtl interface.
Chu and Nahrstedt [16] developed a specialized variant of the CPU reservation abstraction that they called CPU service classes. We have been calling this scheduling abstraction probabilistic CPU reservation in order to make them correspond with the names of other kinds of CPU reservations. Probabilistic CPU reservations are intended to be used to schedule applications whose worst-case CPU utilizations are much larger than their average-case utilizations (for example, MPEG decoders). Each such application gets a CPU reservation that meets its average-case CPU requirement. Furthermore, all applications with probabilistic reservations share an overrun partition--an extra CPU reservation that acts as a server for threads whose demands exceed their amount of reserved CPU time. Since each application is assumed to overrun only a small percentage of the time, the overrun partition is statistically multiplexed among all probabilistic CPU reservations. When demand for the overrun partition collides, the requirements of some applications will not be met.
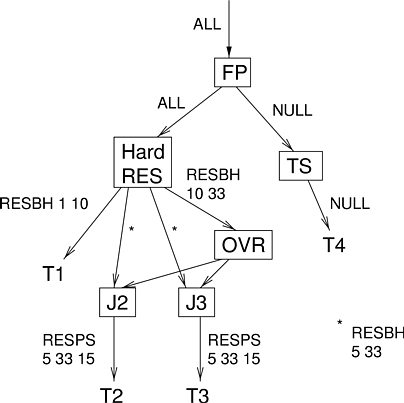
Figure 6.4 shows a scheduling hierarchy that provides probabilistic CPU reservations. Thread 1 has a hard CPU reservation. Threads 2 and 3 are video decoders whose average-case CPU requirements are is 5 ms / 33 ms, and whose maximum CPU requirements are 15 ms / 33 ms. To implement probabilistic reservations, the threads share an overrun partition OVR that has reserved 10 ms / 33 ms. The desired behavior is for each of Threads 2 and 3 to be scheduled from the overrun partition only when they have exhausted the budgets provided to them by the reservation scheduler (that is, when a thread has already run for 5 ms during a 33 ms period, causing the reservation scheduler to refuse to schedule it until the next period begins). To accomplish this, extra information must be passed between the join schedulers and the reservation scheduler. When the reservation scheduler revokes the CPU from a join scheduler (join schedulers were described in Section 5.3.1.2 ), it also includes extra information notifying the join scheduler about why the processor being revoked: possible reasons are (1) the reservation budget has been exhausted and (2) the reservation scheduler has simply decided that another thread is more urgent. Only in the first case should the join scheduler then request scheduling service from the overrun scheduler. Since the overrun scheduler makes no additional guarantee to applications, it can use any scheduling algorithm. EDF would be the best choice in the sense that it would maximize the chances that overrunning applications still meet their deadlines, but a round-robin scheduler could also be used.
|
Like requests for firm and soft CPU reservations, requests for probabilistic CPU reservations could be granted either by loading appropriate rules into the resource manager or by directly manipulating the scheduling hierarchy with the HLSCtl interface.
Kaneko et al. [42] describe a method for integrated scheduling of hard and soft real-time tasks using a single hard real-time task as a server for scheduling soft real-time multimedia applications, amortizing the overhead of Spring’s heavyweight planning scheduler. To implement this using hierarchical scheduling we would put the hard real-time scheduler at the root of the scheduling hierarchy, with the multimedia scheduler at the second level.
Jones et al. [40] developed a scheduler for the Rialto operating system that is designed to support multi-threaded real-time applications. It provides (1) continuous CPU reservations to collections of threads called activities, and (2) time constraints to individual threads, giving them guaranteed deadline-based scheduling. Time granted to an activity by a CPU reservation is divided among the activity’s threads by a round-robin scheduler unless there are active time constraints, in which case threads with active constraints are scheduled earliest-deadline first. CPU time requested to fulfill a new time constraint is first taken from an activity’s reserved time and then (on a best effort basis) from idle time in the schedule. Threads that block during reserved time are allowed to build up a certain amount of credit--they are then given a second chance to meet their deadlines using slack time in the schedule on a best-effort basis. Finally, any remaining free time in the schedule is distributed among all threads on a round-robin basis.
The degree to which a decomposed, hierarchical version of Rialto can be constructed is limited by its integrated approach to managing the time line: CPU reservations and time constraints must share the data structures that represent particular reserved or unreserved time intervals. Furthermore, since time constraints effectively share the pool of unused time in the schedule, it would be difficult to provide a separate constraint scheduler for each activity.
A hierarchical scheduler equivalent to Rialto could be implemented by putting a static-priority scheduler at the root of the scheduling hierarchy that schedules a hybrid reservation/constraint scheduler at the highest priority, a “briefly blocked” scheduler at the middle priority, and finally a round-robin scheduler at the lowest priority. Figure 6.5 illustrates this arrangement. The composite RES+CSTR scheduler manages the time line for reservations and constraints; it schedules an activity scheduler (AC) at any time that it is scheduled either by a reservation or constraint. The RES+CSTR scheduler must also pass extra information to the activity scheduler informing it if a thread is currently being scheduled under a time constraint and, if so, which thread. An activity scheduler always schedules a thread that is running under a time constraint if there is one, and otherwise schedules threads in the activity in a round-robin manner.
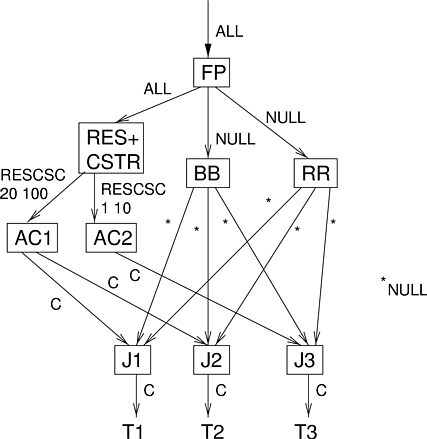
|
The briefly blocked scheduler (BB) records the time at which threads block and unblock, in order to keep track of how much credit each thread has built up. When it gets to run, it picks a thread that has built up credit and schedules it. When there are no briefly blocked threads to run, the round-robin scheduler picks a thread to run and runs it. The 3-way join scheduler for each thread simply runs the thread whenever it is scheduled by any higher-level scheduler. Since Rialto was designed to schedule uniprocessors the case where a join scheduler is scheduled by two schedulers at once does not have to be addressed.
RESCSC and C represent hypothetical guarantees that could be integrated into HLS to support Rialto-style scheduling. RESCSC is a guarantee for a continuous, soft CPU reservation plus time constraints. Since activity schedulers schedule threads in a round robin manner, threads do not receive any guarantee unless they have an active time constraint, indicated by the C guarantee.
To see the benefits of the decomposed version of Rialto, notice that Rialto requires threads within an activity to use time constraints to meet their deadlines since the round-robin activity scheduler is not a real-time scheduler. Since using time constraints may impose a significant burden on the application developer, it may be preferable in some instances to instead schedule the threads in an activity using a rate monotonic scheduler according to the analysis presented in Section 6.1 . To accomplish this, a particular activity would simply need to use a rate monotonic scheduler for its activity scheduler instead of the default Rialto activity scheduler. In fact, the activity schedulers can be replaced with arbitrary application-specific scheduling algorithms: the schedulability of other tasks cannot be adversely affected since the reservation scheduler isolates activities from each other. Also, to support applications that can opportunistically make use of extra CPU time to provide added value, the round-robin idle time scheduler could be replaced with a proportional share scheduler, allowing slack time to be preferentially allocated to applications that can best make use of it. These changes, which would likely require significant implementation effort to make to the original Rialto scheduler, could be made to a hierarchical version of Rialto in a straightforward manner.
Although the hierarchical scheduling architecture supports multiprocessors, the guarantee paradigm does not include explicit multiprocessor support because guarantees are made to schedulers through virtual processors, which by definition can make use of only one processor at a time. Multiprocessor guarantees can be made by providing more than one uniprocessor guarantee.
Since it provides a layer of indirection between applications and schedulers, the resource manager can be used to provide a unified front end to multiple uniprocessor schedulers, effectively merging them into a single multiprocessor scheduler. For example, a reservation scheduler can be instantiated once for each processor on a multiprocessor machine. Since each instance provides guarantees of the same kind, in absence of other constraints the resource manager will ask each scheduler in turn if it can grant a reservation, hiding the fact that there are multiple schedulers from real-time applications. Thus, in this case, the benefits of a multiprocessor reservation scheduler can be attained without actually having to write one. Furthermore, the resource manager can implement useful high-level policies such as putting reservations with similar periods on the same processor, reducing the number of unnecessary context switches. It does not make sense to provide this layer of indirection for a time-sharing scheduler, since time-sharing threads need to be able to move freely between processors in order to balance load.
To support both real-time applications and applications that require the services of a gang scheduler (to concurrently provide CPU time on multiple processors), a tradeoff must be made between the needs of the two different kinds of applications. In other words, a parallel application that cannot make rapid progress without the use of all four processors on a multiprocessor will conflict with a multimedia application that has a CPU reservation on one of the processors: during time reserved by the multimedia application, the parallel application is not able to make progress on any of the four processors. For any particular machine, this conflict is likely to be solved by assumption: either the machine will be part of a dedicated cluster, in which case real-time multimedia is unimportant, or it will be a desktop machine that must perform multimedia computations, in which case any background workload cannot assume reliable simultaneous access to multiple processors.
Integrating a new continuous media scheduler into the HLS framework is not expected to be difficult, as long as whatever guarantee the scheduler makes can be expressed in terms of an existing guarantee. This should be the common case since the existing guarantees cover a wide variety of multimedia schedulers that have appeared in the literature. If a new scheduler does not match any existing type but still fits into the guarantee paradigm (that is, it makes some sort of ongoing guarantee), then a new guarantee type needs to be constructed and rules for converting between its guarantees and those provided by existing schedulers must be written.
Guarantees are static resource reservations that can be used to reason about the composition of schedulers as well as helping to match application requirements to the allocation patterns that schedulers provide. This section discusses some limitations of this paradigm.
A precise guarantee such as a CPU reservation allows an application to be scheduled at a specified rate and granularity. Unfortunately, for a program running on a general-purpose operating system on a modern microprocessor, it can be difficult to map this rate and granularity into a metric that is useful for actual programs, such as a guarantee that a program will be able to get a specified amount of work done--for example, displaying one frame of video or decoding one buffer’s worth of audio data before a deadline.
There are several reasons for this difficulty. First, there is substantial variation in the processors used in personal computers. There are several major CPU manufacturers for personal computers, and each of them has several models of CPUs, sometimes with different available features (floating point, MMX, etc.). Even when machines are identical at the instruction set level, there are different sizes and speeds of caches, numbers of TLB entries, lengths of pipelines, strategies for branch prediction, etc. Second, computer systems differ widely outside of the CPU: disks have different speeds, memory has different latency and bandwidth characteristics, and different I/O bus implementations have widely varying performance characteristics. Also, the overall performance of an application may be heavily influenced by the middleware and device drivers that the application is dynamically bound to. For example, the CPU usage of a game will be dramatically higher when it uses a graphics library that implements all 3D primitives in software than it will when bound to a library that makes use of a powerful hardware graphics accelerator. Furthermore, the performance of complex software artifacts such as graphics libraries can be difficult to characterize because certain common usage patterns are highly optimized compared to other (perfectly valid) usage patterns. Finally, complex applications are not amenable to worst-case execution time analysis. In fact, since they are implemented in Turing-complete languages, it is doubtful that many complex applications can be shown to have any bound on run time, much less a bound that is tight enough to be useful in practice. All of these factors, taken together, imply that it is very difficult to predict application performance in advance. Section 8.5.1 presents a possible method for determining application requirements in the context of a particular hardware and software environment.
Because guarantees describe lower bounds on the amount of CPU time that threads will receive, their applicability for describing the scheduling behavior of complex, dynamic schedulers is limited. This is not a flaw in the guarantee model so much as a consequence of the fact that these schedulers make weak or nonexistent guarantees to entities that they schedule.
Time-sharing schedulers such as the default schedulers in Linux and Windows 2000 provide no real guarantees. And yet they are still useful--millions of people run multimedia applications on these operating systems using the techniques described in Section 3.4. Other classes of schedulers that provide no guarantees to applications include feedback- and progress-based schedulers, hybrid real-time schedulers such as SMART [67], and modified proportional share schedulers like BVT [20] and the modified Lottery scheduler developed by Petrou et al. [71]. The common theme across all of these schedulers is that they attempt to provide high value across the set of all running applications by dynamically allocating CPU time to where it is believed to be needed most. Because these schedulers retain the freedom to dynamically reallocate CPU time, they cannot make strong guarantees to applications: the two are mutually exclusive.
Schedulers that do not make guarantees to applications implicitly assume that applications’ value degrades gracefully when their CPU requirements are not met. For example, they assume that if an application is given 70% of its CPU requirement, the application will provide approximately 70% of its full value. A program that performs real-time computer vision processing of a user’s eye movements might degrade gracefully: when given less CPU than it requires, cursor movements will become jumpy, but they will still track eye movements. On the other hand, computer music synthesis and CD burning applications do not degrade gracefully. If they are given slightly less than their full requirements, they will sound bad and ruin discs, respectively, providing the user with considerably less than their full value.
Since both kinds of applications (gracefully and non-gracefully degrading) may be present in a single system, both should be supported. To accomplish this, a traditional EDF- or RM-based reservation scheduler could be used to provide precise guarantees to applications that do not degrade gracefully. To schedule the remaining applications, one of these two methods could be used:
For threads to be able to receive the scheduling properties that schedulers guarantee, the operating system must not interfere with thread scheduling to the degree that guarantees are violated. Unfortunately, general-purpose operating systems can steal time from applications in order to perform low-level system activities. This time is referred to as stolen because thread schedulers in general-purpose operating systems are not aware of existence. In some cases, the effects of stolen time can be counteracted through over-reservation. For example, if an application requires 10% of the CPU during each 500 ms, than it will have a higher probability of making each deadline in the presence of stolen time if it is assigned a reservation of 15% per 500 ms than if it is assigned a reservation of 11% per 500 ms. However, as Jones and Regehr showed [38], the distribution of stolen time may not follow one of the usual statistical distributions. They described a system that experienced little stolen time until the network interface card was unplugged from the network, at which point a buggy network driver stole 19 ms every 10 seconds. In this situation it is impossible for an application thread with a period shorter than 19 ms to avoid missing a deadline, no matter how much it has over-reserved. Chapter 11 describes two schedulers that provide increased predictability in the presence stolen time.
This chapter has addressed practical issues in guarantee composition. First, we presented a method for scheduling a collection of cooperating threads using a rate monotonic scheduler that is given a CPU reservation. Second, we showed that several complex scheduling behaviors that have appeared in the literature can be composed using a number of small loadable schedulers as basic components. And finally, additional issues and limitations of the guarantee paradigm were discussed.