Because the components of the OSKit are intended to be usable in many different kernel and user-mode environments, it is important that their requirements be defined fully, not only in terms of interface dependencies, but also in terms of execution environment. A component’s execution environment involves many implicit and sometimes subtle factors such as whether and in what cases the component is reentrant. A client using a component must either use an execution environment directly compatible with the environment expected by the component, or it must be able to provide an environment in which the component can run by adding appropriate glue code. For example, most of the OSKit’s components are not inherently thread- or multiprocessor-safe; although they can be used in multithreaded or multiprocessor environments, they rely on the client OS to provide the necessary locking as part of the “glue” the client OS uses to interface with the component.
In order to make it reasonably easy for the client OS to adapt to the execution environment requirements of OSKit components, the execution models used by the OSKit components are purposely kept as simple and easy to understand as possible without sacrificing significant functionality or performance. Another factor driving the OSKit components’ execution models is the goal of being able to integrate large amounts of code, such as device drivers and network protocol stacks, virtually unmodified from traditional kernels such as BSD and Linux; this requirement inevitably places some restrictions on the execution models of the OSKit components derived from these source bases. However, in general, even the execution models of these complex OSKit components are considerably simpler and more well-defined than the original execution environments of the legacy systems from which the components were adapted; this simplification is enabled by carefully-designed OSKit glue code surrounding the legacy code which emulates and hides from the OSKit user the more subtle aspects of the legacy execution environments.
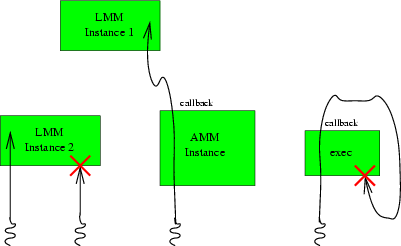
Since the OSKit includes components with a wide range of size and complexity, and as a result different components naturally tend to have different levels of dependence on their execution environment, the OSKit defines a set of standard execution models arranged on a continuum from simplest and least restrictive to most complex and demanding on the client OS. This range of execution models allows the client OS to adopt the simpler OSKit components quickly and with minimal fuss, while still providing all the detailed environment information necessary for the client OS to incorporate the most demanding components. For example, the basic memory-management libraries, LMM and AMM, use an extremely simple execution models with very few restrictions, allowing them to be used immediately in almost any context. The device driver libraries, on the other hand, necessarily place much greater demands on the client since they must deal with interrupts, DMA, and other hardware facilities closely tied to the execution environment; however, these requirements are defined explicitly and generically so that with a little effort even these components can be used in many different contexts.
The remaining sections of this chapter describe each of the execution models used in the OSKit, in order from simplest to most complex. In general, each succeeding execution model builds on and extends the previous model.
The pure execution model is the most basic of the OSKit execution environments; it has the following properties:
Figure 2.1 illustrates the pure execution environment. Since pure functions and components contain no implicit global state, separate “instances” or uses of these components by the client can be treated as completely independent objects: although each individual instance of the component is single-threaded and non-reentrant, the client OS can manage synchronization between independent instances of the component in any way it chooses.
Components that use the impure execution model act just like those operating in the pure model, except that they may contain global shared state and therefore must be treated as a single “instance” for synchronization and reentrancy purposes. For example, many of the functions in liboskit_kern, the kernel support library, set up and access global processor registers and data structures, and are therefore impure. Similarly, some of the functions in the minimal C library, such as malloc and its relatives, inherently require the use of global state and therefore are impure.
The impure execution model has the following properties:
The blocking execution model extends the impure model to support non-preemptive multithreading; it is essentially the execution model used in traditional Unix-like kernels such as BSD and Linux. Components that use the blocking model have the same properties as those that use the impure model, except that they are re-entrant with respect to some callback functions; these functions are known as blocking functions. This means that, whenever the component makes a call to a blocking function, the client OS may re-enter the component in a different context, e.g., in the context of a different thread or processor. The set of callback functions that are assumed to be blocking is part of the component’s contract with the client OS; in general, a function is blocking unless it is explicitly stated to be nonblocking.
In order to use a blocking-model component in a fully preemptive, interruptible, or multiprocessor environment, the client OS must do essentially the same thing to adapt to the component’s execution model as it would for a pure or impure component: namely, it must surround the component with a lock which is taken before entry to the component and released on exit. However, because the component supports re-entrancy through callbacks that are defined to be blocking functions, the client OS’s implementations of these callback functions may release the component’s lock temporarily and re-acquire it before returning into the component, thereby allowing other concurrent uses of the component.
The interruptible blocking execution model, unlike the other models, allows a component to be re-entered at arbitrary points under certain conditions. In the interrupt model, there are two “levels” in which a component’s code may execute: interrupt level and process level. (Note that in this context we use the term “process” only because it is the traditional term used in this context; the components in fact have no notion of an actual “process.”) The interrupt model also assumes a one-bit interrupt enable flag, which the component can control through well-defined callback functions which must be provided by the client OS. When the component is running at either level and interrupts are enabled, the component may be re-entered at interrupt level, typically to execute an interrupt handler of some kind. To be specific, the properties of the interruptible blocking model are as follows:
Although on the surface it may appear that these requirements place severe restrictions on the host OS, the required execution model can in fact be provided quite easily even in most kernels supporting other execution models. The following sections describe some example techniques for providing this execution model.
Global spin lock: The easiest way to provide the required execution model for interruptible, blocking components in a nonpreemptive, process-model, multiprocessor kernel such as Mach 3.0 is to place a single global spin lock around all code running in the device driver framework. A process must acquire this lock before entering driver code, and release it after the operation completes. (This includes both process-level entry through the component’s interface, and interrupt-level entry into the components’ interrupt handlers.) In addition, all blocking callback functions which the host OS supplies should release the global lock before blocking and acquire the lock again after being woken up. This way, other processors, and other processes on the same processor, can run code in the same or other drivers while the first operation is blocked. Note that this global lock must be handled carefully in order to avoid deadlock situations. A simple, “naive” non-reentrant spin lock will not work, because if an interrupt occurs on a processor that is already executing process-level driver code, and that interrupt tries to lock the global lock again, it will deadlock because the lock is already held by the process-level code. The typical solution to this problem is to implement the lock as a “reentrant” lock, so that the same processor can lock it twice (once at process level and once at interrupt level) without deadlocking.
Another strategy for handling the deadlock problem is for the host OS simply to disable interrupts before acquiring the global spin lock and enable interrupts after releasing it, so that interrupt handlers are only called while the process-level device driver code is blocked. (In this case, the osenv_intr_enable and osenv_intr_disable calls, provided by the OS to the drivers, would do nothing because interrupts are always disabled during process-level execution.) This strategy is not recommended, however, because it will increase interrupt latency and break some existing partially-compliant device drivers which busy-wait at process level for conditions set by interrupt handlers.
Spin lock per component: As a refinement to the approach described above, to achieve better parallelism, the host OS kernel may want to maintain a separate spin lock for each component. This way, for example, a network device driver can be run on one processor while a disk device driver is being run on another. This parallelism is allowed by the framework because components are fully independent and do not share data with each other directly. Of course, the client OS must be careful to maintain this independence in the way it uses the components: for example, if the client OS wants to have one component make calls to another (e.g., to connect a file system component to a disk device driver), and it wants the two components to be separately synchronized and use separate locks, the client OS must interpose some of its own code to release one lock and acquire the other during calls from one component to the other.
The issues and solutions for implementing the required execution model in preemptive kernels are similar to those for multiprocessor kernels: basically, locks are used to protect the component’s code. Again, the locking granularity can be global or per-component (or anything in between, as the OS desires). However, in this case, a blocking lock must be used rather than a simple spin lock because the lock must continue to be held if a process running the component’s code is preempted. (Note the distinction between OS-level “blocking,” which can occur at any time during execution of the component’s code but is made invisible to the component’s code through the use of locks; and component-level “blocking,” which only occurs when a component calls a blocking function.)
An alternative solution to the preemption problem is simply to disable preemption while running the component’s code. This solution is likely to be simpler in terms of implementation and to have less overhead, but it may greatly increase thread dispatch latency, possibly defeating the purpose of kernel preemption in the first place.
Many existing kernels, particularly those derived from Unix or BSD, implement a range of “interrupt priority levels,” typically assigning different levels to different classes of devices such as block, character, or network devices. In addition, some processor architectures, such as the 680x0, directly support and require the use of some kind of IPL-based scheme. Although the OSKit device drivers and other OSKit components do not directly support a notion of interrupt priority levels, it can be simulated fairly easily in IPL-based kernels by assigning a particular IPL to each component used by the kernel. In this case, the osenv_intr_disable routine provided by the kernel does not disable all interrupts, but instead only disables interrupts at the interrupt priority level that the client OS has assigned to the calling component, and at all lower priority levels. This way, although the code in each component is only aware of interrupts being “enabled” or “disabled,” the host OS can in effect enforce a general IPL-based scheme.
An obvious limitation, of course, is that all of the device drivers in a particular driver set must generally have the same IPL. However, this is usually not a problem, since the drivers in a set are usually closely related anyway.
Many small kernels use a pure interrupt model internally rather than a traditional process model; this basically means that there is only one kernel stack per processor rather than one kernel stack per process, and therefore kernel code can’t block without losing all of the state on its stack. This is probably the most difficult environment in which to use the framework, since the framework fundamentally assumes one stack per outstanding component invocation. Nevertheless, there are a number of reasonable ways to work around this mismatch of execution model, some of which are described briefly below as examples: